A serverless workflow in Orchestrator refers to a sequence of operations that run in response to user input (optional) and produce output (optional) without requiring any ongoing management of the underlying infrastructure. The workflow is executed automatically, and frees users from having to manage or provision servers. This simplifies the process by allowing the focus to remain on the logic of the workflow, while the infrastructure dynamically adapts to handle the execution.
This is the multi-page printable view of this section. Click here to print.
Serverless Workflows
- 1: Assessment
- 1.1: MTA Analysis
- 2: Infrastructure
- 2.1: Simple Escalation
- 2.2: Move2Kube
- 3: Development
- 4: Workflow Examples
- 5: Troubleshooting
- 6: Best Practices
1 - Assessment
1.1 - MTA Analysis
MTA - migration analysis workflow
Synopsis
This workflow is an assessment workflow type, that invokes an application analysis workflow using MTA and returns the move2kube workflow reference, to run next if the analysis is considered to be successful.
Users are encouraged to use this workflow as self-service alternative for interacting with the MTA UI. Instead of running a mass-migration of project from a managed place, the project stakeholders can use this (or automation) to regularly check the cloud-readiness compatibility of their code.
Workflow application configuration
Application properties can be initialized from environment variables before running the application:
| Environment variable | Description | Mandatory | Default value |
|---|---|---|---|
BACKSTAGE_NOTIFICATIONS_URL | The backstage server URL for notifications | ✅ | |
NOTIFICATIONS_BEARER_TOKEN | The authorization bearer token to use to send notifications | ✅ | |
MTA_URL | The MTA Hub server URL | ✅ |
Inputs
repositoryUrl[mandatory] - the git repo url to examinerecipients[mandatory] - A list of recipients for the notification in the format ofuser:<namespace>/<username>orgroup:<namespace>/<groupname>, i.e.user:default/jsmith.
Output
- On completion the workflow returns an options structure in the exit state of the workflow (also named variables in SonataFlow) linking to the move2kube workflow that will generate k8s manifests for container deployment.
- When the workflow completes there should be a report link on the exit state of the workflow (also named variables in SonataFlow) Currently this is working with MTA version 6.2.x and in the future 7.x version the report link will be removed or will be made optional. Instead of an html report the workflow will use a machine friendly json file.
Dependencies
MTA version 6.2.x or Konveyor 0.2.x
- For OpenShift install MTA using the OperatorHub, search for MTA. Documentation is here
- For Kubernetes install Konveyor with olm
kubectl create -f https://operatorhub.io/install/konveyor-0.2/konveyor-operator.yaml
Runtime configuration
| key | default | description |
|---|---|---|
| mta.url | http://mta-ui.openshift-mta.svc.cluster.local:8080 | Endpoint (with protocol and port) for MTA |
| quarkus.rest-client.mta_json.url | ${mta.url}/hub | MTA hub api |
| quarkus.rest-client.notifications.url | ${BACKSTAGE_NOTIFICATIONS_URL:http://backstage-backstage.rhdh-operator/api/notifications/} | Backstage notification url |
| quarkus.rest-client.mta_json.auth.basicAuth.username | username | Username for the MTA api |
| quarkus.rest-client.mta_json.auth.basicAuth.password | password | Password for the MTA api |
All the configuration items are on [./application.properties]
For running and testing the workflow refer to mta testing.
Workflow Diagram

Installation
2 - Infrastructure
2.1 - Simple Escalation
Simple escalation workflow
An escalation workflow integrated with Atlassian JIRA using SonataFlow.
Prerequisite
- Access to a Jira server (URL, user and API token)
- Access to an OpenShift cluster with
adminRole
Workflow diagram

Note:
The value of the .jiraIssue.fields.status.statusCategory.key field is the one to be used to identify when the done status is reached, all the other
similar fields are subject to translation to the configured language and cannot be used for a consistent check.
Application configuration
Application properties can be initialized from environment variables before running the application:
| Environment variable | Description | Mandatory | Default value |
|---|---|---|---|
JIRA_URL | The Jira server URL | ✅ | |
JIRA_USERNAME | The Jira server username | ✅ | |
JIRA_API_TOKEN | The Jira API Token | ✅ | |
JIRA_PROJECT | The key of the Jira project where the escalation issue is created | ❌ | TEST |
JIRA_ISSUE_TYPE | The ID of the Jira issue type to be created | ✅ | |
OCP_API_SERVER_URL | The OpensShift API Server URL | ✅ | |
OCP_API_SERVER_TOKEN | The OpensShift API Server Token | ✅ | |
ESCALATION_TIMEOUT_SECONDS | The number of seconds to wait before triggering the escalation request, after the issue has been created | ❌ | 60 |
POLLING_PERIODICITY(1) | The polling periodicity of the issue state checker, according to ISO 8601 duration format | ❌ | PT6S |
(1) This is still hardcoded as PT5S while waiting for a fix to KOGITO-9811
How to run
mvn clean quarkus:dev
Example of POST to trigger the flow (see input schema in ocp-onboarding-schema.json):
curl -XPOST -H "Content-Type: application/json" http://localhost:8080/ticket-escalation -d '{"namespace": "_YOUR_NAMESPACE_"}'
Tips:
- Visit Workflow Instances
- Visit (Data Index Query Service)[http://localhost:8080/q/graphql-ui/]
2.2 - Move2Kube
Move2kube (m2k) workflow
Context
This workflow is using https://move2kube.konveyor.io/ to migrate the existing code contained in a git repository to a K8s/OCP platform.
Once the transformation is over, move2kube provides a zip file containing the transformed repo.
Design diagram
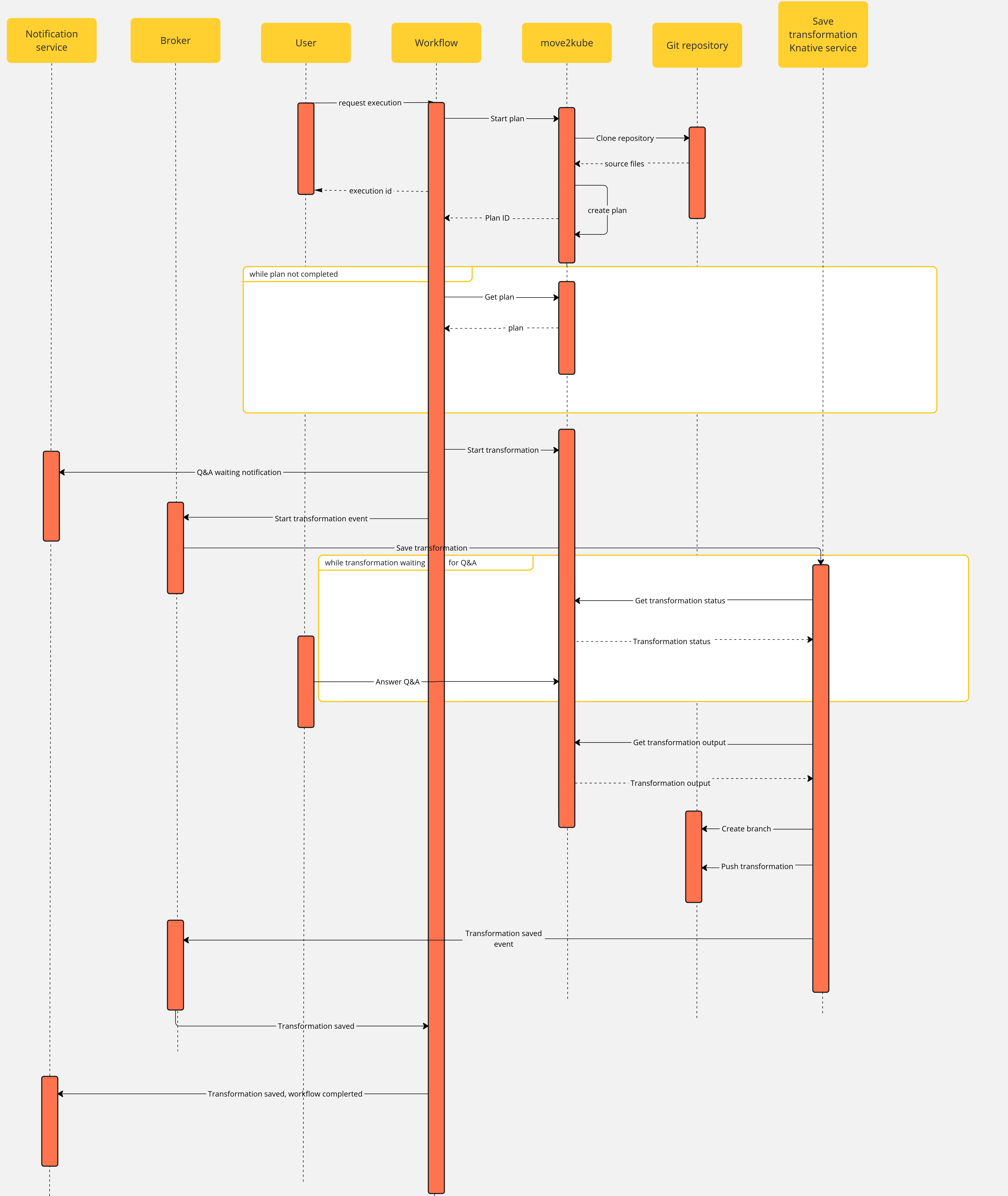

Workflow

Note that if an error occurs during the migration planning there is no feedback given by the move2kube instance API. To overcome this, we defined a maximum amount of retries (move2kube_get_plan_max_retries) to execute while getting the planning before exiting with an error. By default the value is set to 10 and it can be overridden with the environment variable MOVE2KUBE_GET_PLAN_MAX_RETRIES.
Workflow application configuration
Move2kube workflow
Application properties can be initialized from environment variables before running the application:
| Environment variable | Description | Mandatory | Default value |
|---|---|---|---|
MOVE2KUBE_URL | The move2kube instance server URL | ✅ | |
BACKSTAGE_NOTIFICATIONS_URL | The backstage server URL for notifications | ✅ | |
NOTIFICATIONS_BEARER_TOKEN | The authorization bearer token to use to send notifications | ✅ | |
MOVE2KUBE_GET_PLAN_MAX_RETRIES | The amount of retries to get the plan before failing the workflow | ❌ | 10 |
m2k-func serverless function
Application properties can be initialized from environment variables before running the application:
| Environment variable | Description | Mandatory | Default value |
|---|---|---|---|
MOVE2KUBE_API | The move2kube instance server URL | ✅ | |
SSH_PRIV_KEY_PATH | The absolute path to the SSH private key | ✅ | |
BROKER_URL | The knative broker URL | ✅ | |
LOG_LEVEL | The log level | ❌ | INFO |
Components
The use case has the following components:
m2k: theSonataflowresource representing the workflow. A matchingDeploymentis created by the sonataflow operator..m2k-save-transformation-func: the KnativeServiceresource that holds the service retrieving the move2kube instance output and saving it to the git repository. A matchingDeploymentis created by the Knative deployment.move2kube instance: theDeploymentrunning the move2kube instance- Knative
Trigger:m2k-save-transformation-event: event sent by them2kworkflow that will trigger the execution ofm2k-save-transformation-func.transformation-saved-trigger-m2k: event sent bym2k-save-transformation-funcif/once the move2kube output is successfully saved to the git repository.error-trigger-m2k: event sent bym2k-save-transformation-funcif an error while saving the move2kube output to the git repository.
- The Knative
Brokernameddefaultwhich link the components together.
Installation
See official installation guide
Usage
- Create a workspace and a project under it in your move2kube instance
- you can reach your move2kube instance by running
Sample output:oc -n sonataflow-infra get routesNAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD move2kube-route move2kube-route-sonataflow-infra.apps.cluster-c68jb.dynamic.redhatworkshops.io move2kube-svc <all> edge None- for more information, please refer to https://move2kube.konveyor.io/tutorials/ui
- Go to the backstage instance.
To get it, you can run
oc -n rhdh-operator get routes
Sample output:
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
backstage-backstage backstage-backstage-rhdh-operator.apps.cluster-c68jb.dynamic.redhatworkshops.io / backstage-backstage http-backend edge/Redirect None
Go to the
Orchestratorpage.Click on
Move2Kube workflowand then click therunbutton on the top right of the page.In the
repositoryURLfield, put the URL of your git projectIn the
sourceBranchfield, put the name of the branch holding the project you want to transform- ie:
main
- ie:
In the
targetBranchfield, put the name of the branch in which you want the move2kube output to be persisted. If the branch exists, the workflow will fail- ie:
move2kube-output
- ie:
In the
workspaceIdfield, put the ID of the move2kube instance workspace to use for the transformation. Use the ID of the workspace created at the 1st step.- ie:
a46b802d-511c-4097-a5cb-76c892b48d71
- ie:
In the
projectIdfield, put the ID of the move2kube instance project under the previous workspace to use for the transformation. Use the ID of the project created at the 1st step.- ie:
9c7f8914-0b63-4985-8696-d46c17ba4ebe
- ie:
Then click on
nextStepClick on
runto trigger the executionOnce a new transformation has started and is waiting for your input, you will receive a notification with a link to the Q&A
- For more information about what to expect and how to answer the Q&A, please visit the official move2kube documentation
Once you completed the Q&A, the process will continue and the output of the transformation will be saved in your git repository, you will receive a notification to inform you of the completion of the workflow.
- You can now clone the repository and checkout the output branch to deploy your manifests to your cluster! You can check the move2kube documention if you need guidance on how to deploy the generated artifacts.
3 - Development
Serverless-Workflows
This repository contains multiple workflows. Each workflow is represented by a directory in the project. Below is a table listing all available workflows:
| Workflow Name | Description |
|---|---|
create-ocp-project | Sets up an OpenShift Container Platform (OCP) project. |
escalation | Demos workflow ticket escalation. |
extendable-workflow | Provides a flexible, extendable workflow setup. |
greeting | Sample greeting workflow. |
modify-vm-resources | Modifies resources allocated to virtual machines. |
move2kube | Workflow for Move2Kube tasks and transformation. |
mta-v7.x | Migration toolkit for applications, version 7.x. |
mtv-migration | Migration tasks using Migration Toolkit for Virtualization (MTV). |
mtv-plan | Planning workflows for Migration Toolkit for Virtualization. |
request-vm-cnv | Requests and provisions VMs using Container Native Virtualization (CNV). |
Here is the layout of directories per workflow. Each folder contains at least:
application.propertiesthe configuration item specific for the workflow app itself.${workflow}.sw.yamlthe serverless workflow definitions with respect to the best practices.specs/optional folder with OpenAPI specs if the flow needs them.
All .svg can be ignored, there’s no real functional use for them in deployment and all of them are created by VSCode extension.
Every workflow has a matching container image pushed to quay.io by a github workflows
in the form of quay.io/orchestrator/serverless-workflow-${workflow}.
Current image statuses:
- https://quay.io/repository/orchestrator/serverless-workflow-mta-v7.x
- https://quay.io/repository/orchestrator/serverless-workflow-m2k
- https://quay.io/repository/orchestrator/serverless-workflow-greeting
- https://quay.io/repository/orchestrator/serverless-workflow-escalation
After image publishing, GitHub action will generate kubernetes manifests and push a PR to the workflows helm chart repo under a directory matching the workflow name. This repo is used to deploy the workflows to an environment with Sonataflow operator running.
How to introduce a new workflow
Follow these steps to successfully add a new workflow:
- Create a folder under the root with the name of the flow, e.x
/onboarding - Copy
application.properties,onboarding.sw.yamlinto that folder - Create a GitHub workflow file
.github/workflows/${workflow}.yamlthat will callmainworkflow (see greeting.yaml) - Create a pull request but don’t merge yet.
- Send a pull request to serverless-workflows-config repository to add a sub-chart
under the path
charts/workflows/charts/onboarding. You can copy the greeting sub-chart directory and files. - Create a PR to serverless-workflows-config repository and make sure its merge.
- Now the PR from 4 can be merged and an automatic PR will be created with the generated manifests. Review and merge.
See Continuous Integration with make for implementation details of the CI pipeline.
Builder image
There are two builder images under ./pipeline folder:
- workflow-builder-dev.Dockerfile - references nightly build image from
docker.io/apache/incubator-kie-sonataflow-builder:mainthat doesn’t required any authorization - workflow-builder.Dockerfile - references OpenShift Serverless Logic builder image from registry.redhat.io which requires authorization.
Note on CI: For every PR merged in the workflow directory, a GitHub Action runs an image build to generate manifests, and a new PR is automatically generated in the serverless-workflows-config repository. The credentials used by the build process are defined as organization level secret, and the content is from a token on the helm repo with an expiry period of 60 days. Currently only the repo owner (rgolangh) can recreate the token. This should be revised.
4 - Workflow Examples
Our Orchestrator Serverless Workflow Examples repository, located at GitHub, provides a collection of sample workflows designed to help you explore and understand how to build serverless workflows using Orchestrator. These examples showcase a range of use cases, demonstrating how workflows can be developed, tested, and executed based on various inputs and conditions.
Please note that this repository is intended for development and testing purposes only. It serves as a reference for developers looking to create custom workflows and experiment with serverless orchestration concepts. These examples are not optimized for production environments and should be used to guide your own development processes.
5 - Troubleshooting
Troubleshooting Guide
This document provides solutions to common problems encountered with serverless workflows.
Table of Contents
- HTTP Errors
- Workflow Errors
- Configuration Problems
- Performance Issues
- Error Messages
- Network Problems
- Common Scenarios
- Contact Support
HTTP Errors
Many workflow operations are REST requests to REST endpoints. If an HTTP error occurs then the workflow will fail and the HTTP code and message will be displayed. Here is an example of the error in the UI.
Please use HTTP codes documentation for understanding the meaning of such errors.
Here are some examples:
{kind=link}
409. Usually indicates that we are trying to update or create a resource that already exists. E.g. K8S/OCP resources.401. Unauthorized access. A token, password or username might be wrong or expired.
Workflow Errors
Problem: Workflow execution fails
Solution:
- Examine the container log of the workflow
oc logs my-workflow-xy73lj
Problem: Workflow is not listed by the orchestrator plugin
Solution:
Examine the container status and logs
oc get pods my-workflow-xy73lj oc logs my-workflow-xy73ljMost probably the Data index service was unready when the workflow started. Typically this is what the log shows:
2024-07-24 21:10:20,837 ERROR [org.kie.kog.eve.pro.ReactiveMessagingEventPublisher] (main) Error while creating event to topic kogito-processdefinitions-events for event ProcessDefinitionDataEvent {specVersion=1.0, id='586e5273-33b9-4e90-8df6-76b972575b57', source=http://mtaanalysis.default/MTAAnalysis, type='ProcessDefinitionEvent', time=2024-07-24T21:10:20.658694165Z, subject='null', dataContentType='application/json', dataSchema=null, data=org.kie.kogito.event.process.ProcessDefinitionEventBody@7de147e9, kogitoProcessInstanceId='null', kogitoRootProcessInstanceId='null', kogitoProcessId='MTAAnalysis', kogitoRootProcessId='null', kogitoAddons='null', kogitoIdentity='null', extensionAttributes={kogitoprocid=MTAAnalysis}}: java.util.concurrent.CompletionException: io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: sonataflow-platform-data-index-service.default/10.96.15.153:80Check if you use a cluster-wide platform:
$ oc get sonataflowclusterplatforms.sonataflow.org cluster-platformIf you have, like in the example output, then use the namespace
sonataflow-infrawhen you look for the sonataflow servicesMake sure the Data Index is ready, and restart the workflow - notice the
sonataflow-infranamespace usage:$ oc get pods -l sonataflow.org/service=sonataflow-platform-data-index-service -n sonataflow-infra NAME READY STATUS RESTARTS AGE sonataflow-platform-data-index-service-546f59f89f-b7548 1/1 Running 0 11kh $ oc rollout restart deployment my-workflow
Problem: Workflow is failing to reach an HTTPS endpoint because it can’t verify it
REST actions performed by the workflow can fail the SSL certificate check if the target endpoint is signed with a CA which is not available to the workflow. The error in the workflow pod log usually looks like this:
sun.security.provider.certpath.SunCertPathBuilderException - unable to find valid certification path to requested target
Solution:
- If this happens then we need to load the additional CA cert into the running workflow container. To do so, please follow this guile from the SonataFlow guides site: https://sonataflow.org/serverlessworkflow/main/cloud/operator/add-custom-ca-to-a-workflow-pod.html
Configuration Problems
Problem: Workflow installed in a different namespace than Sonataflow services fails to start
Solution:
When deploying a workflow in a namespace other than the one where Sonataflow services are running (e.g., sonataflow-infra), there are essential steps to follow to enable persistence and connectivity for the workflow. See the following steps.
Problem: sonataflow-platform-data-index-service pods can’t connect to the database on startup
- Ensure PostgreSQL Pod has Fully Started
If the PostgreSQL pod is still initializing, allow additional time for it to become fully operational before expecting theDataIndexandJobServicepods to connect. - Verify network policies if PostgreSQL Server is in a different namespace
If PostgreSQL Server is deployed in a separate namespace from Sonataflow services (e.g., not insonataflow-infranamespace), ensure that network policies in the PostgreSQL namespace allow ingress from the Sonataflow services namespace (e.g.,sonataflow-infra). Without appropriate ingress rules, network policies may prevent theDataIndexandJobServicepods from connecting to the database.
6 - Best Practices
Best practices when creating a workflow
A workflow should be developed in accordance with the guidelines outlined in the Serverless Workflow definitions documentation.
This document provides a summary of several additional rules and recommendations to ensure smooth integration with other applications, such as the Backstage Orchestrator UI.
Workflow output schema
To effectively display the results of the workflow and any optional outputs generated by the user interface, or to facilitate the chaining of workflow executions, it is important for a workflow to deliver its output data in a recognized structured format as defined by the WorkflowResult schema.
The output meant for next processing should be placed under data.result property.
id: my-workflow
version: "1.0"
specVersion: "0.8"
name: My Workflow
start: ImmediatelyEnd
extensions:
- extensionid: workflow-output-schema
outputSchema: schemas/workflow-output-schema.json
states:
- name: ImmediatelyEnd
type: inject
data:
result:
completedWith: success
message: A human-readable description of the successful status. Or an error.
outputs:
- key: Foo Bar human readable name which will be shown in the UI
value: Example string value produced on the output. This might be an input for a next workflow.
nextWorkflows:
- id: my-next-workflow-id
name: Next workflow name suggested if this is an assessment workflow. Human readable, it's text does not need to match true workflow name.
end: true
Then the schemas/workflow-output-schema.json can look like (referencing the WorkflowResult schema):
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "WorkflowResult",
"description": "Schema of workflow output",
"type": "object",
"properties": {
"result": {
"$ref": "shared/schemas/workflow-result-schema.json",
"type": "object"
}
}
}